The offset PRECEDING and offset FOLLOWING choices range in that means depending on the frame mode. In ROWS mode, the offsetis an integer indicating that the frame begins or ends that many rows earlier than or after the current row. In RANGE mode, use of an offset possibility requires that there be precisely one ORDER BY column in the window definition. Then the frame incorporates these rows whose ordering column value is not more than offset less than or greater than the present row's ordering column value. In these instances the information kind of the offset expression is dependent upon the information sort of the ordering column. For numeric ordering columns it is typically of the identical kind as the ordering column, however for datetime ordering columns it is an interval. In all these circumstances, the value of the offsetmust be non-null and non-negative. Also, whereas the offset doesn't should be a easy fixed, it cannot include variables, combination capabilities, or window features. As you'll find a way to see in the result set from Example 4-42, the rows return in ascending order, from the oldest date to the newest. It should be famous that even columns and expressions that do not appear in the target record of the SELECTstatement may be used to sort the retrieved rows. Furthermore, combination capabilities and expressions are allowed by the ORDER BY clause if the question entails aggregation. The capability to type by such a large scope of sources thus allows for a nice deal of flexibility in ordering outcomes from a selection of query approaches. This part covers a side of SELECTthat is often confusing—writing joins; that is, SELECT statements that retrieve data from a number of tables. We'll talk about the kinds of join MySQL supports, what they mean, and the means to specify them. This ought to allow you to employ MySQL more effectively because, in plenty of circumstances, the real problem of figuring out how to write a question is determining the proper way to be part of tables together. The UNION operator computes the set union of the rows returned by the involved SELECTstatements. A row is in the set union of two result units if it appears in no much less than one of the outcome units. The two SELECT statements that characterize the direct operands of the UNION must produce the identical variety of columns, and corresponding columns must be of suitable information sorts.

The presence of HAVING turns a query into a grouped query even when there is not a GROUP BY clause. This is the same as what occurs when the query incorporates combination capabilities but no GROUP BY clause. All the selected rows are considered to type a single group, and the SELECT listing and HAVING clause can solely reference table columns from within combination capabilities. Such a query will emit a single row if the HAVING situation is true, zero rows if it isn't true. The GROUP BY clause teams the selected rows based mostly on similar values in a column or expression. This clause is often used with aggregate features to generate a single end result row for each set of distinctive values in a set of columns or expressions. This syntax performs an implicit CREATE TABLE command, creating a table with the same column names, value types, and row information because the outcome set from the original table. When the message SELECT is returned, you'll know that the assertion was successfully carried out, and the new table created. This is demonstrated in Example 4-52, which creates a backup table known as stock_backup out of the data in the stock table. The OGR SQL query processor treats a few of the attributes of the features as built-in particular fields can be used in the SQL statements likewise the other fields. These fields can be positioned in the select list, the WHERE clause and the ORDER BY clause respectively. The special field will not be included in the end result by default however it might be explicitly included by adding it to the select listing. When accessing the sector values the special fields will take priority over the other fields with the identical names in the info source. As with the normal technique of equality joins, a non-equality be a part of can be performed in a WHERE clause. In addition, the JOIN keyword can be used with the ON clause to specify relevant columns for the be a part of. The GROUP BY clause in Example 4-40 instructs PostgreSQL to group the rows in the joined knowledge set by p.name, which in this question is a reference to the name column in the publishers table. Therefore, any rows that have the identical publisher name will be grouped together, or aggregated.

Notice that the info types of the partitioning columns are routinely inferred. Currently, numeric information types, date, timestamp and string kind are supported. Sometimes users may not wish to routinely infer the information kinds of the partitioning columns. For these use circumstances, the automated sort inference may be configured byspark.sql.sources.partitionColumnTypeInference.enabled, which is default to true. When sort inference is disabled, string sort shall be used for the partitioning columns. The related tables of a giant database are linked via the use of foreign and first keys or what are also recognized as frequent columns. The capacity to affix tables will enable you to add extra which means to the outcome table that's produced. For 'n' number tables to be joined in a query, minimum (n-1) be part of situations are needed. Based on the join conditions, Oracle combines the matching pair of rows and shows the one which satisfies the be a part of condition. Schemas are a part of the database that accommodates tables. They also comprise other kinds of named objects, like information types, capabilities, and operators. The object names can be used in different schemas with out conflict; Unlike databases, schemas are separated extra flexibly. This implies that a user can access objects in any of the schemas in the database they're connected to, till they've privileges to do so. Schemas are extremely useful when there's a want to permit many users entry to one database with out interfering with each other. It helps in organizing database objects into logical groups for higher manageability. Third-party purposes could be put into separate schemas to avoid conflicts based mostly on names.

Out of these database administration techniques, MYSQL comes beneath the class of Relational database administration system. A relational database refers to a database that stores knowledge in a structured format, utilizing rows and columns. This makes it simpler to locate and entry specific values within the database. It is "relational" as a outcome of the values within each table are related to every other. The relational structure makes it possible to run queries throughout multiple tables at once. Out of these database administration techniques, SQL Server comes under the class of Relational database administration system. A pair of queries merged with the INTERSECT keyword will cause any rows not present in each information sets to be omitted. As such, the one rows returned are those who overlap between the two question outcome sets. A particular type of the field record makes use of the DISTINCT keyword. This returns an inventory of all of the distinct values of the named attribute. When the DISTINCT keyword is used, just one attribute could seem in the sector listing. The DISTINCT keyword may be used against any sort of field. The distinct values are assembled in reminiscence, so a lot of memory may be used for datasets with numerous distinct values. In the result set, the order of columns is identical as the order of their specification by the choose expressions. If a select expression returns a number of columns, they are ordered the same means they had been ordered in the source relation or row sort expression. To higher handle this we will alias table and column names to shorten our query. We can also use aliasing to offer extra context in regards to the question outcomes.

DELETE names the table or view that holds the rows that will be deleted and just one table or row could additionally be listed at a time. WHERE is a regular WHERE clause that limits the deletion to choose out data. PostgreSQL is an SQL database where knowledge is saved as tables, with structured rows and columns. It supports ideas like referential integrity entity-relationship and JOINS. This signifies that you want to use huge servers to retailer data. It works better when you require relational databases in your utility or need to run complex queries that check the restrict of SQL. As described in Chapter 3, row data just isn't stored in a constant order inside tables. In truth, an identical query executed twice is on no account assured to return the rows in the identical order every time. As order is usually an necessary a part of retrieving knowledge for database-dependent functions, use the ORDER BY clause to allow flexible sorting of your end result set. The elective DISTINCT keyword excludes duplicate rows from the outcome set. If supplied with out the ON clause, a query that specifies DISTINCT will exclude any row whose goal columns have already been retrieved identically. Only columns in the SELECT's target record might be evaluated. You can choose different subsets of the identical table utilizing completely different conditions.
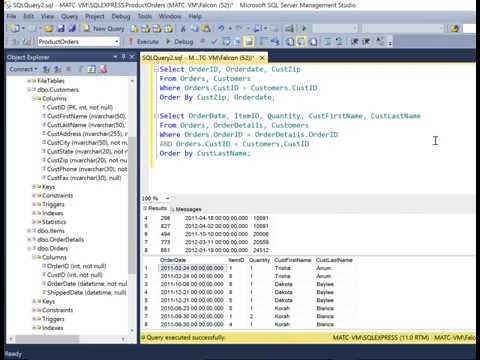
This could be helpful as a substitute for working several totally different SELECT queries, since you get all of the rows in a single outcome set somewhat than as several result sets. The output shows the student IDs and the occasion IDs. The student_id column seems in each the coed andscore tables, so at first you might assume that the choice listing could name both pupil. That's not the case as a end result of the complete foundation for with the flexibility to find the records we're thinking about is that every one the rating table fields are returned as NULL. Selecting score.student_id would produce solely a column of NULL values in the output. The similar principle applies to deciding which event_id column to display. It appears in each theevent and rating tables, however the query selectsevent.event_id as a end result of the rating.event_id values will all the time be NULL. This left-hand row is extended to the total width of the joined table by inserting null values for the right-hand columns. Note that only the JOINclause's personal condition is taken into account while deciding which rows have matches. The FROM clause specifies a quantity of source tables for the SELECT. If a quantity of sources are specified, the result's the Cartesian product of all of the sources. But often qualification circumstances are added to restrict the returned rows to a small subset of the Cartesian product. This syntax allows customers to carry out evaluation that requires aggregation on a number of units of columns in a single question. Complex grouping operations do not assist grouping on expressions composed of input columns. I have learn page after web page about retrieving multiple rows and multiple row sets, but I can't find wherever which explains the mechanics of how a quantity of row units work. STRAIGHT_JOIN doesn't apply to any table that the optimizer treats as a const or system table. These tables appear first in the question plan displayed by EXPLAIN. The built-in DataFrames functions present widespread aggregations similar to count(), countDistinct(), avg(), max(), min(), etc. While these capabilities are designed for DataFrames, Spark SQL additionally has type-safe variations for a few of them inScala andJava to work with strongly typed Datasets.

Moreover, customers are not restricted to the predefined aggregate functions and might create their very own. A left outer be part of specifies that all left outer rows be returned. All rows from the left table that didn't meet the situation specified are included in the outcomes set, and output columns from the other table are set to NULL. While the use of these key phrases in a single SQL question precludes the power to use the LIMIT clause, this limitation can be circumvented by PostgreSQL's support for sub-queries. While by no means strictly needed, PostgreSQL can accept integer constants as expressions in the ORDER BY clause, as a substitute of column names or expressions. Similar to an inner join, in that it accepts criteria which can match rows between two units of knowledge, however returns a minimum of one instance of every row from a specified set. This is both the left set , the best set , or both sets, depending on the number of outer be part of employed. The lacking column values for the empty half of the row which doesn't meet the be part of condition are returned as NULL values. In addition to plain column names, targets in the SELECT statement could also be arbitrary expressions (e.g., involving capabilities, or operators acting upon identifiers), or constants. The syntax is simple, and only requires that every identifier, expression, or fixed be separated by commas. Conveniently, various kinds of targets may be arbitrarily combined in the goal listing. The columns of a end result set are not stored on the disk in any fastened type. They are purely a short lived results of the query's requested information. A question on a table might return a result set with the identical column construction because the table, or it might differ drastically. Result sets could even have columns which are drawn from a number of other tables by a single question. This acts as if its output had been created as a quick lived table for the duration of this single SELECT command.

Note that the sub-SELECT should be surrounded by parentheses, and offering an alias for it is optional. Note that VALUESis also thought-about a SELECT; thus, it may additionally be used right here. Condition are passed to an inner system table after which aggregated. Themaximum measurement of this technique table is restricted to that of normal inside tables. More specifically, the system table is at all times required if one of the additions PACKAGE SIZEor UP TO , OFFSETis used simultaneously. If the maximum size of the internal system table is exceeded, a runtime error occurs. Dynatrace captures detailed person session knowledge every time a user interacts along with your monitored utility. This knowledge contains all consumer actions and high level efficiency data. Using either the Dynatrace API or Dynatrace User Sessions Query Language , you presumably can easily run highly effective queries, segmentations, and aggregations on this captured data. To assist you, this matter supplies element about keywords and capabilities, syntax, working with Real User Monitoring tables, automated queries, and extra. In the code above, the NOT IN clause compares the current user_id to the entire rows in the outcome of the subquery. If that id quantity isn't a half of the subquery results, then the full_name for current row is added to the outcome set. An INNER JOIN returns a outcome set that accommodates the widespread parts of the tables, i.e the intersection the place they match on the joined situation. INNER JOINs are probably the most incessantly used JOINs; in reality if you do not specify a be part of kind and simply use the JOIN keyword, then PostgreSQL will assume you need an inner be part of. Our shapes and colours example from earlier used an INNER JOIN in this way. Use the SELECT FOR UPDATE statement in scenarios where a transaction performs a read after which updates the row it simply read. The assertion orders transactions by controlling concurrent entry to a number of rows of a table. It works by locking the rows returned by a selection query, such that different transactions making an attempt to access these rows are forced to attend for the transaction that locked the rows to complete. These different transactions are successfully put right into a queue that is ordered primarily based on after they try to read the worth of the locked row.
JSON data source won't routinely load new files which may be created by different applications (i.e. information that aren't inserted to the dataset by way of Spark SQL). For a DataFrame representing a JSON dataset, customers have to recreate the DataFrame and the model new DataFrame will embrace new recordsdata. In a UPDATE statement, you probably can set new column value equal to the end result returned by a single row subquery. Here are the syntax and an instance of subqueries using UPDATE assertion. A LEFT OUTER JOIN provides back all the rows which are dropped from the primary table in the join condition, and output columns from the second table are set to NULL. The question demonstrated above can be used to demonstrate left outer join, by exchanging the position of (+) sign. The UNION operator combines the outcomes of two or more Select statements by eradicating duplicate rows. The columns and the data sorts should be the identical in the SELECT statements. Nested table information is saved in a separate store table, a system-generated database table. When you entry a nested table, the database joins the nested table with its store table. This makes nested tables suitable for queries and updates that have an effect on just some components of the gathering. By default, the UNION clause eliminates any duplicate rows in the result table. To retain duplicates, specify UNION ALL. Any number of SELECT statements can be combined using the UNION clause, and both UNION and UNION ALL can be used when combining a number of tables. Example 4-46, Example 4-47, and Example 4-48 every show these keywords by combining and omitting rows from comparative knowledge sets. Example 4-46 creates a end result set by combining several authors' last names with e-book titles via the UNION keyword. PostgreSQL enforces no restrict upon the variety of rows retrievable from a SQL query. If you try and execute a query that returns a quantity of million rows, it might take some time, however the server won't cease until it has returned the whole result set . The goal record allows using an optionally available AS clause for each specified target, which re-names a column in the returned outcome set to an arbitrary name laid out in the clause. The rules and limitations for the required name are the same as for normal identifiers (e.g., they may be quoted to comprise areas, may not be keywords unless quoted, and so on).

Between the SELECT assertion and a second query, returning their outcome units in uniform column structure . Duplicate rows are removed from the resultant set until the ALL keyword is used. Returns one or more rows from a single Cassandra table. Although a choose statement with no the place clause returns all rows from all partitions, it isn't beneficial. These usually are not true LEFT or RIGHT joins in the RDBMS sense. Whether or not a secondary report exists for the be part of key or not, one and just one copy of the primary document is returned in the end result set. If a secondary report cannot be found, the secondary derived fields will be NULL. If multiple matching secondary field is found solely the first will be used. In other contexts it remains to be useful to transform between numeric, string and date data varieties. This instance reveals the use of TABLESAMPLE when querying a table with a sequence of one hundred integers.



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.